
Multiple options are available for developers and architects when it comes to using stream-based components. Each solution has its own specialty and particular ideal use case. If you are looking for scalable solutions that are capable of handling massive amounts of incoming data, however, then two names that come to mind are either Kafka or Redis (Redis streams, to be more precise). In this review, I will quickly explain both solutions so that you can decide for yourself which is the most suitable solution for your problems.
What exactly is a stream?
Before moving forward, let me ask the following: What exactly is a stream? Keeping it simple, a stream is a sequence of data elements spread out over time. In contrast to sending a large quantity of data all together in a batch, the stream sends the data element by element as if the data were on a conveyor belt. The way stream-based architectures work is by having one or more content producers sending their elements to a centralized location (called Brokers in Kafka terminology) which then forward the data to the receivers. In addition to be effective for handling real-time data, the added benefit of stream-handling systems (also known as message queues) is that they can act as buffers for that data. This helps to create systems that are always responsive, even if the volume of incoming messages is too big for the processing portion. Having a buffer between producers and consumers helps the consumers to work at their own pace. This is in contrast to directly connecting producers and consumers, which could potentially overflow consumers when the influx of data is just too much for them to handle. This would generate a loss of data and system downtime, which are problems that message queues are trying to solve.
What is Kafka?
Apache Kafka (or Kafka for brevity) is a streaming solution that must be considered if a data stream is to be handled in the architecture. The key feature (amongst many) of Kafka is that it was designed to handle extensive amounts of information with utmost resiliency. Originally designed with log-processing in mind, Kafka can be configured to handle up to 30 million events per second. However, it is true that correctly installing Kafka and configuring it to reliably handle that amount of traffic is not trivial because there are vast amounts of information that can be used. However, the community around the solution is one of its main benefits. The basics of Kafka can be understood using three key concepts: Brokers, Topics, and Partitions. The figure below is a high-level overview of Kafka’s architecture.
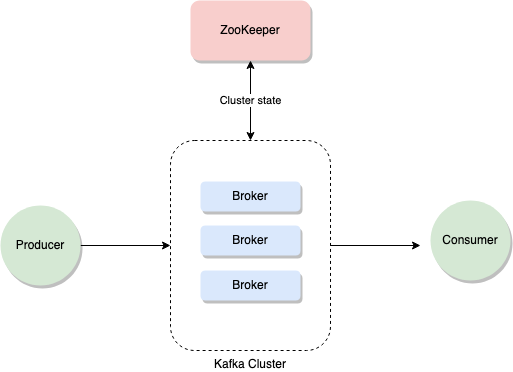
The architecture shows how the Kafka Cluster is composed of Brokers. These Brokers are stateless, with the ZooKeeper (another component required for the Cluster to work) in charge of maintaining the state of the entire Cluster. This helps to recover from a Broker malfunction because it is the ZooKeeper that is in charge of deciding who is master and who is not among all Brokers. Messages sent by Producers are stored in Topics. These can be thought of as logical channels, meant to help you organize and categorize your messages. Consumers will use these Topics to extract only the messages they are interested in. Finally, each Topic can be partitioned and each partition stored inside a different Broker. Kafka will replicate the received information as many times as it is instructed to do (also known as the replication factor), thus allowing the Cluster to recover from a failure (if one of the Brokers stops working) without losing any data.
What are Redis streams?
Redis is probably one of the best known in-memory databases. It provides key-value storage with a simple architecture that can achieve a very high I/O throughput. One of the most common use cases for Redis is caching. Using its in-memory store and coupled with its ability to set a TTL (time to live) on its records, this is a perfect match for a high-performing cache layer. Redis was originally designed to run on Linux. However, if you are more comfortable working with Windows, Memurai is a native Windows port of Redis that has been derived from Microsoft’s OpenTech Redis project and which is being actively maintained. Memurai is available free of charge, with commercial subscription licenses also available. Many people are not aware that a feature of Redis (and Memurai) is that it can be used to handle streams. Indeed, Redis has been supporting Pub/Sub mechanics the longest, which most readers probably already know about. Pub/Sub allows different applications to communicate using Redis as a message bus: i.e., a client publishes a “message” on a “channel,” and any client “listening” to that “channel” receives that “message.” Streams take this concept to the next level. Unlike Pub/Sub, stream clients can read messages long after they have been pushed into the stream. Also, messages themselves persist using AOF and RDB persistency methods if enabled. Finally, Redis streams are functionally very equivalent to Kafka. The following is a summary of the features of Redis streams:
-
Unlike with Pub/Sub, messages are not removed from the stream once they are consumed.
-
Redis streams can be consumed either in blocking or nonblocking ways.
-
Messages inside the stream will have a key value structure (instead of simply being a string) and will have a unique, sequenced ID.
-
Because of this, consumers can request a range of IDs from anywhere in the stream.
-
This means that if a consumer crashes, it can pick up right from where it left, even if the window of inactivity is large enough to have received multiple messages in between. This is a significant benefit in comparison with Pub/Sub, where the message is published and if there are no subscribers, then no one will ever get it.
-
Messages persist in AOF and RDB.
-
Essentially, Redis streams are a brand new way of using this powerful NoSQL database to handle asynchronous communication between producers and consumers. Redis aims to use a slightly different approach to solve the same problems that Kafka solves.
High availability and fault tolerance
Tackling high availability and fault tolerance has become the main objectives of most distributed systems because it means being able to continue to function, even during a potentially big failure. This is because distributed systems are built on top of the premise that “errors happen”; thus, because errors cannot be avoided, they should be planned for in the system architecture. Hence, the concepts of high availability and fault tolerance are incorporated into these systems. Because they are so similar, these concepts are occasionally confused with each other and a quick review of each is given here:
- Fault tolerance: This is the ability to recover from a potentially catastrophic failure without losing data in the process. Essentially, the platform is capable of accepting and working with problems, but it may not be available for use during that time.
- High availability: This means that the platform is always reachable, even during a failure scenario. It does not mean that it will work as expected during that time, but it will be reachable, and given the right data-retention policies, it might not lose data in the process.
Handling failure on Kafka vs. Redis streams
Kafka
Kafka is a distributed system, which means that it can (or rather should) be configured to run on multiple different servers. With this configuration, the system has the ability to replicate the data received onto multiple servers and keep a synced version of it. In case of a Broker failure, the ZooKeeper will catch the failure and promote one of the back-up Brokers to be the new lead. It will then update every client connected to the Brokers about this change. This behavior provides Kafka with two of the major features that any streaming-ready component must have:
- The ability to resist failure (i.e., to avoid data loss during a failure of one of the distributed components).
- The ability to remain available during that process. If, in the future, the failed Broker is reincorporated into the Cluster, the Zookeeper will once again intervene and update the Cluster structure accordingly.
Redis (or Memurai) streams
To talk about Redis streams in the present context is to talk about Redis, since the underlying architecture is that of the main database. Thus, Redis itself provides high availability through a component known as Sentinel. It is itself a distributed system that can monitor and provide failover policies to the different instances of Redis that may be running. Sentinel works with a master–slave mechanism, which means that only a single instance of Redis will act as a master node at any given time. If it goes down for some reason, one of its slave nodes will pick up the mantle. The cluster version of Redis also implements high availability and partition resistance (i.e., when parts of the cluster get isolated due to failures) using a very intricate logic to communicate and share slaves between nodes. Furthermore, the cluster configuration of Redis provides fault tolerance by sharding the data and having a similar internal master–slave node configuration. All nodes of the clusters are constantly pinging each other to find “holes” in the mix and once one is detected, it will reconfigure itself to promote an appropriate slave.
When would one or the other be used?
Both options covered here show very similar (if not identical) features. The differences are more on the needed level of resiliency to achieve and how much setup and maintenance costs can be sustained.
Kafka
Kafka is an enterprise production grade solution with a high degree of resiliency and robustness. However, setting up, configuring, and maintaining Kafka is not trivial. The cost of the physical (powerful) servers or virtual machines should also be considered.
Redis/Memurai
Redis (on Linux) and Memurai (on Windows) are also enterprise production-grade solutions with similar levels of resiliency and robustness, but they can be deployed with xcopy and be set up in 2 minutes, while their maintenance costs are close to zero. An army of single developers are currently using Redis and Memurai in their single-master configurations.
Final conclusion
Streaming data is a very common architectural system because it solves a problem that we must deal with daily: i.e., there is just too much data available. Processing incoming data in real time as it is received can be a daunting task, especially for complex data processing. However, having a streaming buffer between producers and consumers can be a very smart arrangement. In such a case, both Kafka and Redis streams can work exceptionally effectively because they provide all the features we would expect from a streaming solution and can scale as much as is needed. Is one better than the other, objectively speaking? No, but if we consider the context, i.e., the problem to be solved, the familiarity of the team with the technology, the expected traffic to handle, and other factors unique to the context, then making the choice between Kafka and Redis streams should not be that difficult.
Redis is a trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by Memurai is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Memurai