
As a developer, you might use an in-memory cache for a bunch of reasons. Sometimes you need data consistency across machines; other times you need high-availability so that your data is still accessible when one of your servers goes down. But in most cases, you use caching to improve the speed of accessing your data. And that means the underlying technology needs to be lightning fast.
That’s why we’ve invested so much time and effort into optimizing Memurai’s performance. We’ve worked long and hard to ensure it will run blisteringly fast on production systems and to make its speed competitive with Redis. The results of our optimization work are shown below.
In this article we’ll demonstrate how to recreate the setup that we used to test our work with redis benchmark. From the very beginning, we designed it to be completely reproducible. This way, you can verify the claims that we make and tune the setup for your own hardware configurations, so you can run your own tests.
The Methodology to test Memurai and Redis Performance
The initial step when designing our benchmark comparison was to decide which hardware to run our performance tests on. We knew we wanted to use a public cloud that offered bare metal machines for three major reasons. First off, we didn’t want virtualization technology to affect the results. Secondly, we wanted to keep all machines inside the same data center to minimize network traffic interference. And lastly, running our tests in a public environment allows anyone to reproduce our findings.
After checking out the options, we chose Packet because it offers a wide selection of cloud-based bare metal machines, which makes it perfect for running performance benchmarks and tests.
For our comparison, we spun up three machines all using Packet’s “c1-xlarge” configuration: one to run Memurai 1.0.8 on Windows Server 2016 Standard, one to run Redis 5.0.5 on Linux, and the other to run the redis-benchmark command-line tool on Linux. Both of the Linux machines were running Ubuntu 16.04 LTS. We also ensured that all the machines were connected to the same network switch.
Operating systems need to support a wide range of workloads, so it’s rare for them to be properly tuned for performance tests. We disabled transparent hugepages on the Redis machine and Windows Defender on the Memurai machine to minimize interference while the tests were running, and crucially, made sure these machines were only running the benchmarks and had no other activity going on.
The Benchmark
redis-benchmark is a utility that’s distributed as part of Redis. The test is designed to be simple, so you can quickly get performance numbers to evaluate your hardware and Redis instance. It’s also designed to be realistic and simulates running commands from multiple clients in parallel.
We ran redis benchmark test using the following commands:
for i in {1..300}; do
time ./redis-benchmark -h 10.88.92.130 --csv -P 1 -n 200000 >>results-P1.csv
time ./redis-benchmark -h 10.88.92.130 --csv -P 16 -n 200000 >>results-P16.csv
done
This code executes redis-benchmark a total of 600 times: 300 with pipelining disabled (-P1) and the other 300 with pipelining 16 commands (-P16). The reason that we executed each test 300 times was to account for variance in the results — network benchmark results typically exhibit a wide spread. We took the median value of all the runs for each test to calculate a final score.
By default, redis-benchmark simulates 50 clients in parallel, and a client only sends its commands when the response to the previous command is seen. With Redis’ pipelining feature, it is possible to send multiple commands at once. This is something that real-world applications and redis client libraries attempt to do since it can vastly improve performance.
If you’re new to benchmarking, this article contains some useful caveats to be aware of when comparing the performance of Redis against another cache or data store. The main thing to keep in mind for our comparison is that Memurai is Redis-compatible — it doesn’t suffer from any of the apples to oranges comparisons that plague other benchmark results. We’re measuring the same commands, in the same order, working on the same data.
The Results
We want to say up front: all benchmark results should be interpreted with a grain of salt. And our results are no different. redis-benchmark test is trustworthy, but it’s still a synthetic benchmark. If you run the tests in this comparison, the results you see will depend on your machine configuration, network, and a whole host of other factors. If you want to know how Memurai will perform relative to Redis for your environment, reproducing our tests is essential.
The results of comparing Memurai against Redis are provided below. The following charts are broken down by query type and pipelining setting (using the -P option). They show the percentage gains with Memurai for each query type against Redis.
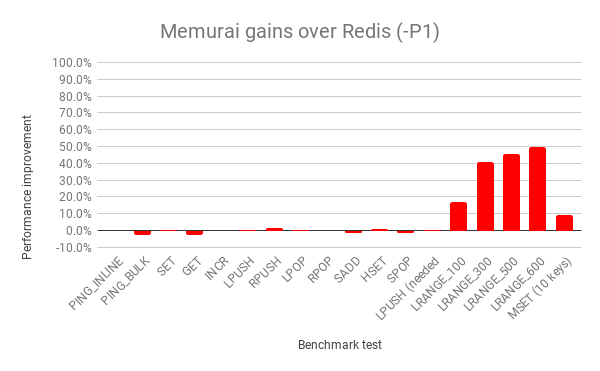
Fig 1.0 shows that performance of Redis and Memurai is comparable for most of the tests when using the -P1 option, with some marginal gains and losses that are within the noise. It’s a different story, however, for the LRANGE_* and MSET benchmark tests, and you can see a blatantly obvious improvement over the Redis scores. And when increasing the pipelining value to 16, the difference is even starker.
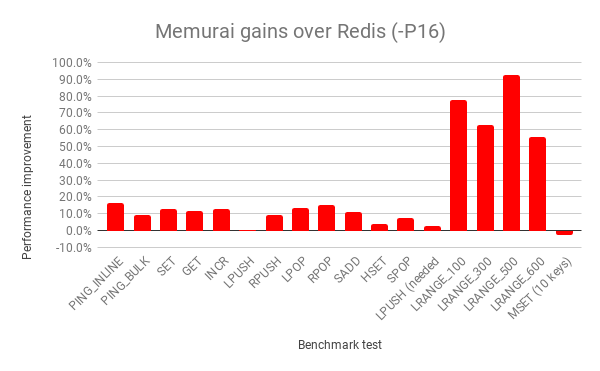
Fig 2.0 demonstrates how pipelining helps recognize significant gains over Redis. The majority of the tests in fig 2.0 show more than a 5% improvement over Redis on Linux. But again it’s in the LRANGE_* results that Memurai shines. These benchmark results illustrate the dramatic improvement pipelining provides when working with Memurai, and each of the LRANGE_* tests shows over a 50% improvement when compared with Redis.
Conclusion: the performance of Memurai the Redis Windows alternative
Performance is crucial for developers using in-memory caches. Memurai brings an enterprise-grade cache and data store to Windows and benefits from the considerable amount of time we’ve poured into improving its performance. The results above show Memurai easily matches Redis for the majority of the queries in the synthetic redis-benchmark workload, and for some queries performs over 50% better when pipelining is used, making Memurai a competitive alternative to Redis for Windows environments.
Redis is a trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by Memurai is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Memurai