
Why the Xilinx Alveo U280* is not appropriate for Big Data analytics
Technical articles and news about Memurai.
In my early career, I spent several years as a compiler and developer in Microsoft C++. For the last eight years, I have worked on distributed systems and Big Data analytics.
Currently I manage Memurai, a Windows native in-memory cache compatible with Redis™*.
During the fall of 2019, I tried to "merge" my two different fields of experience and I bought a Xilinx Alveo U280 Data Center Accelerator Card (Alveo U280) to experiment with Big Data analytics on field-programmable gate arrays (FPGAs). For the purpose of this article, I am assuming that readers are familiar with FPGAs.
My findings after six months of working with the Alveo U280 card are presented in this article.
Defining the objective
The objective was to understand whether the Alveo U280 card (and/or any other off-the-shelf FPGA "data center" card) is an appropriate choice for Big Data computing.
My definition of Big Data is quite simple: it is a dataset with at least 1 billion rows. Smaller datasets than this fit into traditional databases.
The operation I selected for the test was an SQL JOIN operation. This is a single operation that is virtually used in any nontrivial SQL query, yet it is complex enough to give an indication of the performance level of a piece of hardware, even though the workload is not strictly SQL.
The core activity of the JOIN operation is to sort the data of the two tables that are participating in the JOIN operation. Hence, my experiment started with coding and sorting on the Alveo U280, but did not progress beyond sorting.
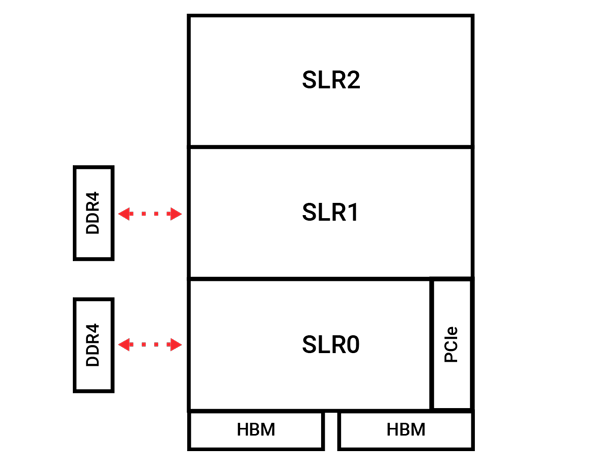
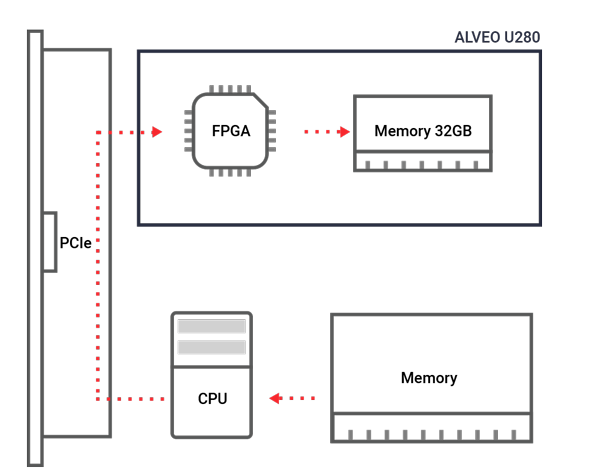
The Alveo U280 architecture
Like any other FPGA data center card, the Alveo U280 is a card that is inserted into a PCIe slot in a workstation or server.
The Alveo U280 has 32GB of DDR4 memory, which is normal memory on a personal computer (PC), and inside the chip itself, it has 8GB of super advanced high bandwidth memory (HBM) (U280 architecture link). HBM is 3D stacked memory with huge memory bandwidth. It can achieve this bandwidth because of its 16 physical memory channels (32 pseudo channels). An abundance of memory channels fits well with working with Big Data datasets, which occupy large amounts of memory.
Programming model (C++ or VHDL/Verilog)
The uniqueness of modern FPGA cards (not only Xilinx but also Intel) is that they can be programmed with high-level synthesis (HLS) C++. HLS is the opposite of hardware description languages (HDL), such as VHDL or Verilog, which are lower-level languages.
Programming an FPGA card in C++ clearly reduces experimentation time, and most importantly, reduces the number of development iterations (code -> compile -> test -> fix or change -> compile -> …). It is worthwhile remembering that compiling for FPGA, either with HLS or HDL, takes a long time. With HLS C++, one is also limited in what can be used in the language (for example, one cannot experiment much with pointers). However, just the fact that functions and classes to abstract the code can be used is very useful1.
The software development tool, vitis, is difficult to install and configure. For example, one needs to manually install several missing libraries, manually overwrite some bad files, etc. However, Xilinx is working very hard on the software, and their forums are full of answers, while their customer support staff are very responsible. So I am not particularly worried about the software development tool, which will improve.
Although I have quite a decent idea (presumably like most readers of this article) of how the CPU and the caches work, it is necessary to understand that learning to program in an HDL (such as VHDL or Verilog) takes a considerable amount of time. The paths for hardware and software developer careers are completely different. This means that if one is a software developer (like myself), HLS tools are the only choice if one wants to program an FPGA card.
Programming model details
To sort large quantities of numbers while taking full advantage of the hardware, and given the memory limitations of the Alveo U280, it is necessary
- to fit the data in the 8GB HBM memory, which means that there cannot be more than 1 billion 64-bit numbers, and
- to fully use the 16 HBM memory channels.
As any good C++ developer would do, I started creating small "kernels" (or functions) and tested them. They almost saturated the memory channels, which was exciting for me. However, each memory channel is quite "slow". We can compare it to a normal DDR4 memory channel in our servers, which means we need to write many kernels (each kernel using a few channels) and then merge the data, etc.
This is not easy since there is a limit to the number of kernels that can be put on the die. In fact, the limit is on the number of inputs and outputs of the kernels. There is an I/O crossbar with 32 ports, of which a maximum of 31 ports can be utilized.
I learned a lesson from this and wanted to change from many small kernels to a few big kernels. However, the Alveo U280 is divided into three areas, and each kernel must fit into a single area, which means that the kernels cannot be too big.
The real obstacle
I designed a kernel small enough to fit into one area, but complex enough to sort data at very high speed. This is where I experienced the real obstacle to this experiment.
The kernel consisted of four basic components or "functions".
- Read data stream A.
- Read data stream B.
- Merge and sort data streams.
- Write final stream to memory.
Each of those kernels, when tested individually, showed great performance.
However, when put together and tested, showed very poor performance, just a few percent of what I was expecting.
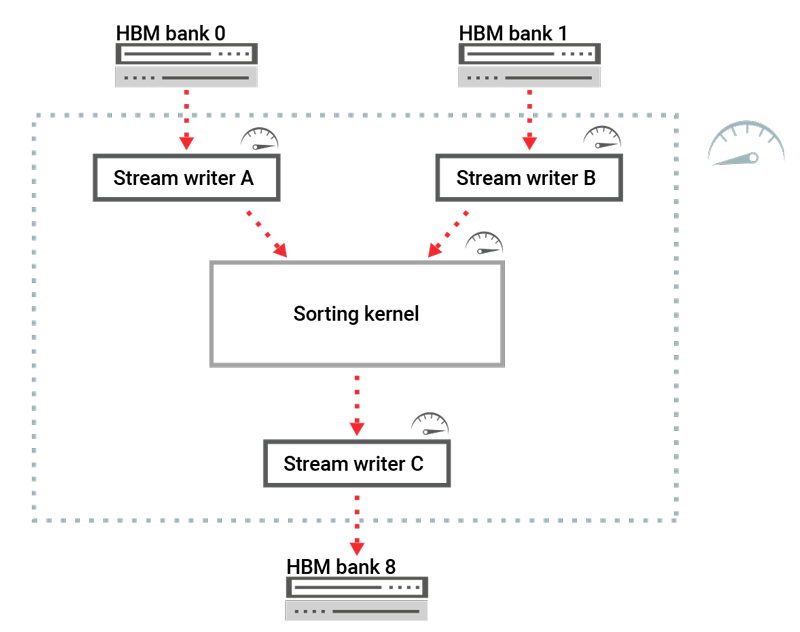
The conclusion was simple: the C++-to-VHDL compiler was not designed to take C++ and generate hardware with such "functions" in parallel. The C++ HLS compiler is inherently single threaded.
So the real obstacle is that to achieve high speed, many small kernels must be written that work in parallel with each other. However, this is limited by the FPGA area and the I/O crossbar, as noted above.
Memory bounded
Another significant obstacle in utilizing the Alveo U280 (or for that matter, any other FPGA card) is the amount of fast memory (HBM for the Alveo) present in the card (8GB for the Alveo HBM). If the dataset is bigger than the card memory (which presumably it is since we are considering Big Data), then transfers to and from the DDR4 memory present on the card or in the server must be taken into account, as well as the associated engineering complexities. For the Alveo U280 card, data is transferred between the host computer and the Alveo card via the PCIe bus at a maximum speed of about 20GB/s.
Summarizing the weaknesses
Based on the results of my experiments, I summarize my perception of the weaknesses of the Alveo U280 card as follows.
- You can't write truly concurrent micro kernels.
- You can't truly saturate all HBM memory channels.
- You can't hold large datasets in memory (HBM is only 8GB).
Comparative test with a traditional PC
AMD Epyc processors have 64 physical cores (128 logical) plus an astounding eight memory channels link. A dual socket AMD Epyc gives 16 memory channels, with a theoretical transfer rate of 400GB/s, which is slightly less than what the Alveo U280 theoretically gives.
Because I did not have the budget for such systems, I bought a "simple" AMD Threadripper 3970X with "only" 32 physical cores (64 logical) and four memory channels link.
I spent two hours installing the latest GCC and the latest TBB to experiment with parallel sorting. With a few lines of code, I could get the following results for sorting 64-bit numbers.

Conclusions
The results I obtained from my experiments with Big Data and the Alveo U280 card enabled me to draw certain conclusions.
First, writing a few C++ lines to sort tens of billions of numbers and getting the sorting done in seconds is still not achievable with current FPGA technologies. In addition, when Intel cards are considered, the blocking factor also includes the compiler technology.
Unfortunately, taking the VHDL route for development is too slow for most companies. It is also clear that a good VHDL engineer is still difficult to replace with software 😊.
Finally, working with C++, development iterations can be done in minutes, while hours, if not days, are needed with VHDL.
Disclaimer
I do not hold stocks or any other financial products, nor do I have any contract or direct or indirect involvement, with the mentioned companies: Xilinx, Intel, and AMD. This is true for myself and my family. However, if AMD were to provide a double socket AMD Epyc I would happily rerun their test 😊.
*The complete name of the card is: “Alveo U280 Data Center Accelerator Card”.
Redis is a trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by Memurai is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Memurai